Guide SEO > Technique > Robots.txt
Utile au référencement naturel pour éviter d’indexer des contenus dupliqués, le fichier robots.txt a plus d’un tour dans son sac.
En plus de fournir le sitemap aux robots, il indique à un moteur de recherche quelles zones de votre site internet il peut indexer ou non.
Alors, quel est le rôle exact d’un fichier robots.txt ? Comment mieux comprendre son fonctionnement pour une utilisation optimale ?
Qu’est-ce que le protocole Robots.txt ?
Imaginons que vous souhaitiez interdire l’accès des robots Google à certaines pages de votre site, pour empêcher l’indexation dans les résultats de moteur de recherche par exemple. En plaçant le fichier robots.txt à la racine de votre site internet, les googlebots vont prendre connaissance de la liste de ressources à ne pas explorer. Et c’est pareil pour tous les autres moteurs de recherche !
Quoi qu’il arrive, un crawler visitera toujours en premier lieu le fichier robots.txt, situé à l’adresse http://www.mon-site-web/robots.txt. C’est également dans ce fichier qu’est indiqué l’emplacement du fichier sitemap.xml.
A noter : si vous placez votre fichier robots.txt dans un répertoire par exemple, les crawlers ne pourront prendre connaissance des pages à ne pas parcourir et ne suivront pas les consignes fixées. Toujours rédigé en minuscule (pas de ROBOTS.TXT) et d’une taille inférieure à 62 Ko, le fichier robots.txt doit donc être OBLIGATOIREMENT placé à la racine du site.
Le fichier robots.txt est-il important ?
Rien ne vous oblige de placer un fichier robots.txt à la racine de votre site internet. Gardez tout simplement à l’esprit qu’un site web sans fichier robots.txt sera intégralement parcouru par les crawlers. En conséquence, toutes les pages du site web seront indexées dans les SERPS.
L’intérêt du fichier robots.txt se trouve dans la faiblesse de certaines zones de votre site (non sécurisées par exemple). Dans ce cas, vous avez tout intérêt à signaler aux robots de ne pas indexer ces pages.
Attention : certains robots peuvent ignorer votre fichier robots.txt. C’est notamment les cas des robots malveillants, envoyés par les concurrents qui souhaitent aspirer votre site.
Que regarde précisément un robot d’indexation ?
Prenons le cas du site https://www.referenseo.com/.
Lorsqu’un crawler analyse le site, il commence par télécharger et analyser le fichier robots.txt, qui lui permet de définir les URLs qu’il est autorisé à explorer. En fonction des autorisations, il télécharge ensuite l’URL https://www.referenseo.com/. Après avoir analysé le contenu de la page et extrait les liens internes, il passe aux liens externes. Le téléchargement des données continuent jusqu’à ce que le robot n’en trouve plus de nouvelles.
Comment créer le contenu d’un fichier robots.txt ?
Un fichier robots.txt comprend deux instructions : User-agent et Disallow. L’instruction User-agent permet de définir à qui s’appliquent les règles (Google, Bing, Yahoo, etc.), tandis que l’instruction Disallow précise les pages ou répertoires à ne pas explorer.
Exemples :
User-agent : Googlebot
Disallow : /page-1.html
Disallow : /page-3.html
Disallow : /page-7.htmlIci, le fichier robots.txt interdit aux robots Google d’explorer trois pages distinctes du site web. Autre cas :
User-agent : *
Disallow : /Ce type de fichier robots.txt bloque totalement les robots d’exploration, tous moteurs de recherche confondus. C’est-à-dire que votre site internet ne sera pas lu par les crawlers et de ce fait, ne sera pas indexé dans les SERPS.
Dernier exemple :
User-agent : *
Disallow : /repertoire-a/
Disallow : /page-7.htmlLa valeur * signifie » tous les moteurs de recherche ». Cette commande interdit ainsi à tous les robots l’exploration du répertoire A et de la page 7 du site web.
On peut aussi bloquer l’accès à des fichiers et répertoires spécifiques commençant par une donnée personnalisée :
User-agent : *
Disallow : /bonjour*Dans cette situation, tous les fichiers et répertoires commençant par « bonjour » ne seront pas explorés.
A savoir : un fichier robots.txt est accessible au public. N’importe qui peut voir ce que vous ne souhaitez pas faire indexer. Exemple :
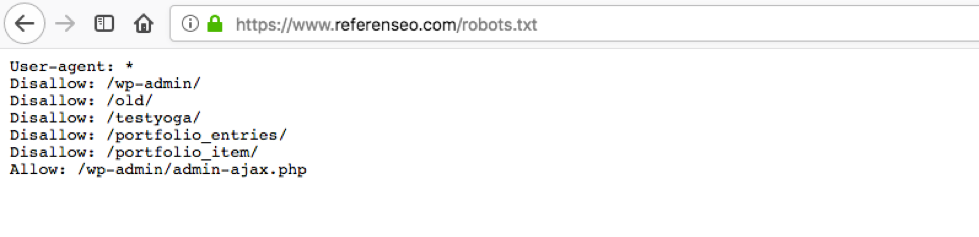
Il faut savoir qu’une page web bloquée par un robot peut tout de même être indexée. C’est notamment le cas si elle est référencée ailleurs sur le web. Pour éviter ce genre de situation, il convient de protéger les fichiers du serveur par un mot de passe, d’utiliser la balise meta noindex ou encore l’en-tête de réponse.
Comment tester un fichier robots.txt ?
Première chose à faire : créer et authentifier votre site internet sur Google Search Console. Une fois cette manipulation effectuée, il vous suffit de cliquer dans le menu Couverture, puis sur Exclues puis sur Bloquée par le robots.txt. Exemple ci-dessous :
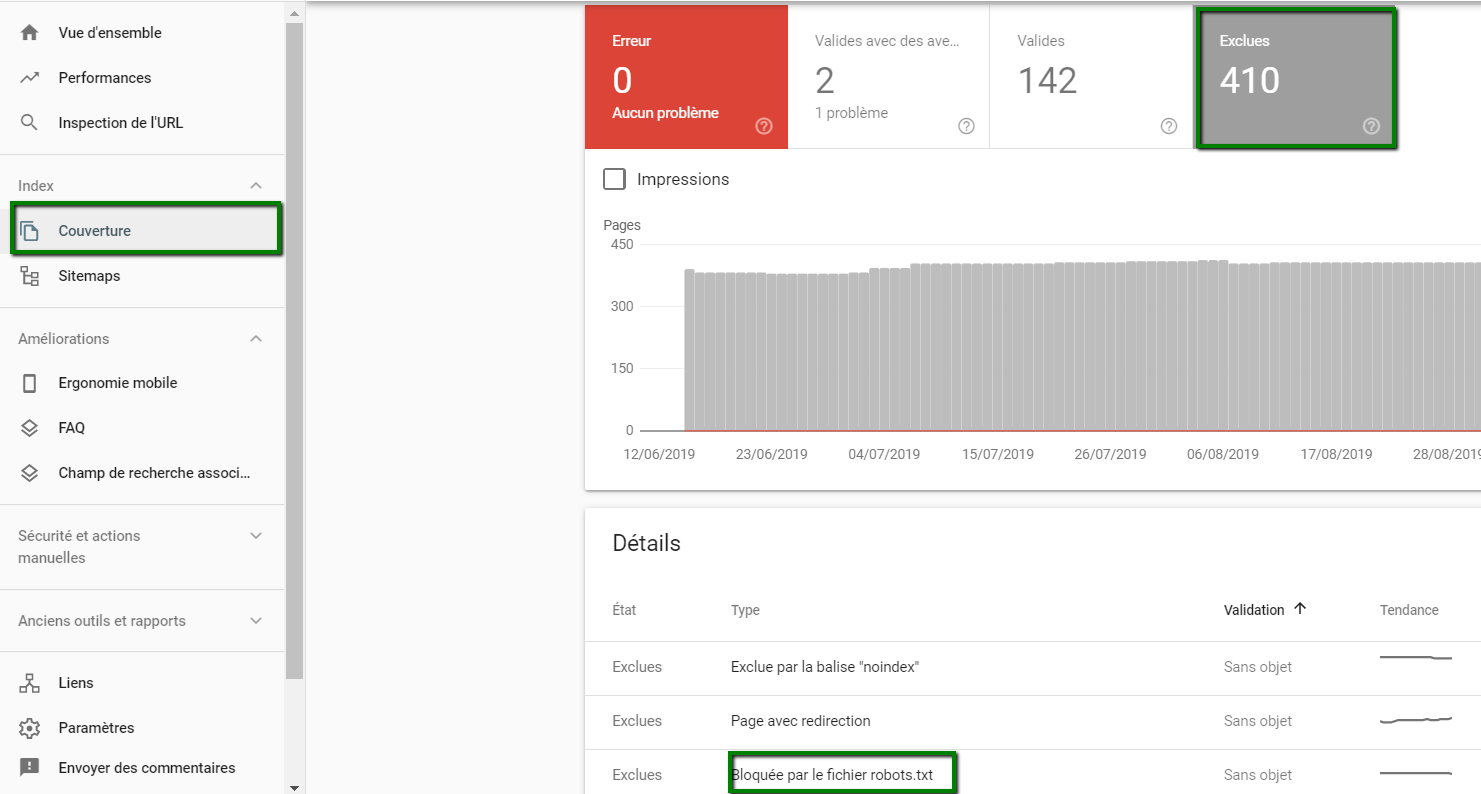
Vous découvrirez ainsi toutes les pages bloquées par les robots de moteur de recherche !
En conclusion
Un fichier robots.txt n’est pas un protocole de sécurité pour empêcher les actes de malveillance. Il est uniquement destiné au choix de l’indexation des pages par le webmaster.
En outre, c’est un précieux allié pour éviter le duplicate content, en refusant aux robots de parcourir les pages au contenu dupliqué, par exemple.
Pour une désindexation plus radicale, pensez également à la balise noindex (ce qui évitera à votre site internet d’être indexé à cause d’autres sites web qui feraient un lien vers vous). A vous de jouer maintenant !